

Ten AI safety projects I'd like people to work on
Listicles are hacky, I know. But in any case, here are ten AI safety projects I'm pretty into.

If you’re interested in applying for funding to work on one of these projects (or something similar), check out our RFP.
I’ve said it before, and I’ll say it again: I think there’s a real chance that AI systems capable of causing a catastrophe (including to the point of causing human extinction) are developed in the next decade. This is why I spend my days making grants to talented people working on projects that could reduce catastrophic risks from transformative AI.
I don't have a spreadsheet where I can plug in grant details and get an estimate of basis points of catastrophic risk reduction (and if I did, I wouldn't trust the results). But over the last two years working in this role, I’ve at least developed some Intuitions™ about promising projects that I’d1 like to see more people work on.
Here they are.
1. AI security field-building
What: Design and run a field-building program that takes security engineers (with at least a few years of work experience) and teaches them about the types of security challenges most relevant to transformative AI: securing model weights and algorithmic insights from highly resourced adversaries, preventing data contamination, defending against exfiltration attacks, etc. The program would also give actionable advice on how to break into the field. This could look like a 6-week, part-time discussion group covering a curriculum of AI security readings. It could also involve some type of “buddy system” where participants are paired with mentors working on AI security (a la MATS).
Why this matters: It would be unfortunate if powerful AIs were stolen by bad guys. Keeping AI projects secure seems important for making transformative AI go well, and progress on this looks tractable. Though I understand that there are a few AI security talent development projects already in the works, I’ve heard that talent bottlenecks are a persistent problem (especially for security roles that aren’t at AI labs, as these positions offer much lower salaries).
What the first few months could look like: Designing and getting feedback on a curriculum (or finding someone to do this for you), figuring out the program structure, reaching out to potential mentors/guest speakers, and hiring an ops person.
2. Technical AI governance research organization
What: Start a research organization that primarily focuses on the kinds of technical AI governance topics outlined in this paper. It could also run a fellowship program (e.g., 3-6 months, with a part-time option for people who already have jobs) that allows early- to mid-career technical people to explore a technical AI governance project, build greater context on AI safety, and develop connections with others in the field. “Technical AI governance” is a pretty broad/vague term, so it’s probably worth narrowing down to a few complementary directions, at least to start. Here are a few from the Bucknall/Reuel et al. paper that I’m particularly excited about.
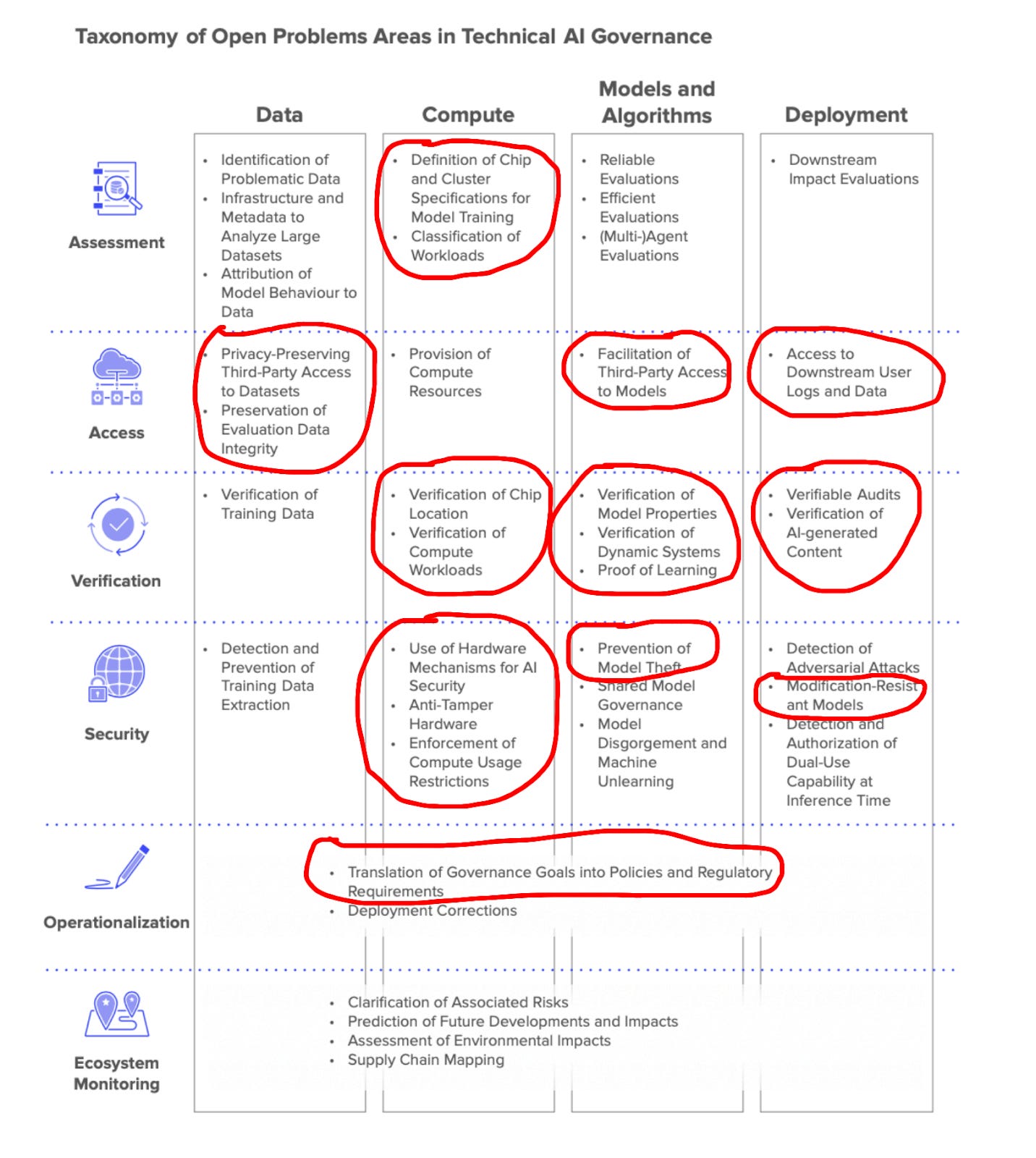
Why it matters: Rigorous technical analysis on questions like "how would you actually enforce [insert compute governance mechanism] in practice?" or "what techniques can allow for verifiable model auditing without compromising model security?" can be extraordinarily helpful for making policy proposals more feasible (and thus more likely to be implemented). My sense is that a lot of AI safety people have gotten excited about this paradigm in the last year or so (justifiably IMO), but there’s still more room for this kind of work. See Open Problems in Technical AI Governance for more. FAR AI also recently ran a workshop on this.
What the first few months could look like: Figuring out which subset of technical AI governance research areas to focus on (if you haven’t done this already), speaking to people working on those kinds of problems to get possible research project ideas, and hiring a few researchers.
3. Tracking sketchy AI agent behaviour “in the wild”
What: Start an organization to systematically investigate deployed AI agents for signs of misalignment, scheming, or general sketchy behaviour in the wild. This could involve a number of possible activities: (1) partnering with AI companies to analyze anonymized interaction logs for concerning behaviour patterns, (2) creating honeypot environments to see if AI agents attempt to gain unauthorized access or resources, (3) interviewing power users of AI agents (e.g., companies) to gather preliminary signals of situations where agents might be doing sketchy things, and (4) writing about case studies of deployed agents acting sycophantic, manipulative, deceptive, etc.
The organization could also publish detailed case studies of confirmed incidents and maintain a public database of problematic behaviours observed in deployed systems (though only ones relevant to misalignment, and not “AI harm” more broadly construed).
Why this matters: For a long time, folks worried about misalignment mostly on the basis of theoretical arguments (and occasionally some lab experiments with questionable ecological validity). Things have changed: LLMs are starting to exhibit increasingly sophisticated and concerning behaviour, such as attempting to prevent their preferences from being changed, systematically gaming their evaluation tasks, and aiming for high scores rather than actually solving the problems at hand. We should go a step further and try hard to check if these concerns are actually manifesting in real-world deployments (and if so, in what ways and at what scale). Thoughtful, rigorous, and real-world observational evidence about misalignment would be valuable for grounding policy discussions and improving the world's situational awareness about AI risk.
What the first few months could look like: Picking 1-2 workstreams to start with, speaking with people working on relevant topics (e.g., at AI companies) to understand challenges/opportunities, and learning more about how other OSINT projects work (to understand analogies and disanalogies).
4. AI safety communications consultancy
What: A dedicated communications firm specializing in helping organizations working on AI safety communicate more effectively about their work. The firm would employ communications professionals who can build (or already have) AI context. They'd provide a range of core communications support services — media training, writing support, strategic planning, helping to pitch op-eds to editors, interview prep, developing messaging frameworks, etc. Unlike general communications firms, this firm would invest in understanding the nuances of AI safety to provide more effective support (which IMO is really helpful). Importantly, at least one of the founders should have experience working at a communications firm — I love bright generalists, but this really demands some prior experience and connections.
Why this matters: Communicating clearly about AI risk is crucial for informing policy discussions and building public understanding, but many organizations working on narrow technical problems simply aren't suited to do this well. A researcher focused on a niche technical topic probably doesn’t know how to pitch an op-ed to a major publication or land a TV interview. Many organizations hire people to help with this, but in many instances, having in-house staff doesn’t make sense, and it’s hard to find consultants who understand these issues well. A new consultancy could help to solve this problem.
What the first few months could look like: Talking to potential clients to understand their needs and challenges, doing (or commissioning) research on messages/frames/messengers, and generally getting a bird’s-eye view of the AI safety ecosystem.
5. AI lab monitor
What: An independent organization (or even a single talented person if they’re really good) that conducts meticulous analysis of frontier AI labs' safety-relevant practices and policies. They'd track and analyze safety testing procedures and what safeguards labs actually implement, check whether responsible scaling policies are being followed (and whether there are ways they can be strengthened), critically examine labs' plans for navigating periods of rapid AI progress, dig into corporate governance structures, and generally document all safety-relevant decisions these companies are making. Alongside a constant stream of analysis on specific topics of interest, this effort might also produce semi-regular (e.g., quarterly) scorecards rating labs across key dimensions.
Why this matters: Running a frontier AI lab involves designing and implementing complicated safety practices that are constantly evolving. This is an enormous challenge, and the decisions made by AI labs today could be crucial for avoiding catastrophic outcomes over the next few years. When labs update their safety policies, modify security requirements, or change evaluation procedures, the implications can be subtle but significant (and sometimes these changes are buried in long technical reports). We need people whose bread and butter is obsessively tracking these details — and importantly, effectively communicating their findings in ways that lead to engagement by policymakers, AI lab employees, and the broader AI safety community. This kind of rigorous external analysis serves multiple purposes: it helps labs improve and stay accountable to their practices, it gives policymakers reliable information about how safety practices are being implemented, and it improves the public’s situational awareness about crucial decisions being made by the most important companies in the world.
What the first few months could look like: Developing a comprehensive tracking system for monitoring lab activities (RSS feeds for blog posts, paper releases, job postings, etc.), producing a few short-ish analyses to learn more about what potential consumers of this analysis find useful, building relationships with current/former lab employees, and establishing distribution channels for your analysis (Substack, Twitter presence, a newsletter, a website, maybe a database, relationships with journalists who cover AI, etc).
6. AI safety living literature reviews
What: A “living literature review” is a continuously updated collection of expert-authored articles on a specific topic. It would be great if there were a few of these for core AI safety topics. Questions like: What's the state of evidence for AI systems engaging in scheming? Which technical AI safety research agendas are people working on, and what progress has been made? What policy ideas have people floated for making AI safer (bucketed into categories of policy ideas)? Will there really be major job losses before transformative AI arrives? Each review would be maintained by a single expert (or small team) who synthesizes the memesphere into digestible, regularly updated articles.
Why this matters: The AI safety field would benefit from more high-quality synthesis. Every week brings new papers, blog posts, Twitter threads, and hot takes. Meanwhile, policymakers, funders, and even researchers themselves struggle to maintain a coherent picture of what is going on. Living literature reviews seem like an interesting and under-explored model for helping with this.
What the first few months could look like: Picking a single topic to focus on, writing some introductory material, reading up on anything where you have gaps in your knowledge, and then producing something that summarizes the current discourse on that topic. You'd also want to set up the basic infrastructure — a Substack for publishing, a simple website, a Twitter account for distribution, and a system for tracking new research and analysis (RSS feeds, Google Scholar alerts, maybe just following the right people on Twitter).
7. $10 billion AI resilience plan
What: A comprehensive, implementation-ready plan detailing how $10 billion (somewhat arbitrarily chosen) could be deployed to make significant progress toward AI alignment/control research and/or societal resilience measures. This would ideally be a fairly detailed blueprint with specific program structures, priority funding areas, budget allocations, timelines, milestones, etc.
Why this matters: Going from "we should spend more on AI safety" to “here’s how we can spend more on AI safety” is non-obvious, yet we might be in this scenario if, e.g., a major government (not necessarily the US government; even smaller countries have big budgets) wakes up to transformative AI risk or if philanthropic interest spikes after some big warning shot.
What the first few months could look like: Interviewing relevant experts (e.g., AI safety researchers, policy people, funders) to inform your view on the top priorities, researching existing large-scale research funding programs (DARPA, NSF, etc.) to see if there’s anything you can learn, developing a taxonomy of different intervention areas (ideally with rough budget allocations), and creating a few concrete "shovel-ready" program proposals that could quickly absorb significant funding.
8. AI tools for fact-checking
What: An organization (possibly a for-profit) that builds AI-powered fact-checking tools designed for transparency and demonstrable lack of bias. One example product could be a browser extension that fact-checks claims in real-time. Unlike other AI research tools (e.g., Deep Research), this could prioritize visible chain-of-thought reasoning and open-source code to make it more trustworthy. The organization would ideally conduct rigorous bias evaluations of its own tools, publish research papers, and maintain public datasets of fact-checking decisions. Beyond the browser extension, they could develop APIs for platforms to integrate fact-checking.
Why this matters: Better societal epistemics would be valuable for many obvious reasons, but we’d really benefit from tools that help to provide decisionmakers with quality information — especially when AI is causing rapid and unprecedented societal change. It’s hard to overstate how important smart decision-making will be if our institutions get stress-tested by fast AI progress.
What the first few months could look like: Probably you’d want to follow basic sensible advice on starting a company — for example, this book apparently has a good reputation. I haven’t run a startup before, so take this with a giant grain of salt, but I’d guess it would be good to find good advisors, experiment with a basic MVP, research existing fact-checking methodologies and their limitations, and talk to potential users to understand what they actually want.
9. AI auditors
What: Start a company to build AI agents that can conduct compliance audits. These systems would automate the labor-intensive tasks that might otherwise be performed by human auditors: reviewing documentation and logs, checking implementation of safety procedures, etc. Critical caveat: this would need extraordinarily careful implementation. Giving AI systems a bunch of access to labs' internal systems creates massive attack surfaces — the AI auditors could be compromised in a variety of ways.
Why this matters: Human-led safety audits would be expensive, time-consuming, and face inherent trust problems. AI auditors could theoretically enable more frequent and comprehensive compliance checks while avoiding information leakage (you can much more easily wipe an AI's memory compared to a human). However, the security risks of implementing this carelessly would be severe: an adversary could compromise the auditor to falsely certify unsafe practices or to introduce some vulnerabilities into the lab. I honestly wouldn't be surprised if security folks at AI labs would see this and think "absolutely not, no way we're letting an AI system have that kind of access" — and honestly, fair enough. But I think it’s a cool enough idea that merits more exploration.
What the first few months could look like: Again, probably you’d want to follow something close to this. I haven’t run a startup before, so take this with a giant grain of salt, but I’d guess it would be good to find good mentors/advisors, research existing auditing proposals, and talk to people at labs to understand constraints that might not be obvious from the outside.
10. AI economic impacts tracker
What: An organization focused on examining how AI is transforming the economy, through both original research and reporting. They'd do things like: survey workers in management roles about how often they use AI (and in what contexts), conduct economics-style research to understand AI’s contribution to worker productivity (like this study by METR, or this paper but not bullshit), and investigate whether/how AI is impacting hiring decisions at large companies (e.g., this was a big claim — is it true?). Think Epoch’s approach but applied to economic impacts rather than compute, algorithmic progress, energy usage, and other capabilities measures. They might partner with companies to get granular deployment data, commission longitudinal studies following specific firms as they integrate AI, and maintain a comprehensive database of AI adoption metrics that researchers and policymakers could use to make sense of AI’s diffusion across the economy. Anthropic’s Economic Futures program is pretty similar to what I have in mind.
Why this matters: Current approaches to tracking AI progress — training compute, benchmark scores, capability demos, energy usage — are valuable but paint an incomplete picture. There's often a massive gap between "AI can nail the bar exam" and "AI is meaningfully changing how paralegals do their jobs", and we’d benefit from more people combing through the data (and in some cases, going out and gathering it) to make sense of that gap. An organization focused on producing analysis at this level of abstraction could make it easier to tell how close we are to truly wild societal impacts.
What the first few months could look like: Talking to the folks working on this at Anthropic (and other labs if they’re doing similar work), identifying 2-3 specific sub-areas to focus on initially (and doing a really solid job at analyzing them before expanding), hiring support staff (e.g., RAs), and getting a bunch of advisors to review your work.
Caveats, hedges, clarifications
Here are some important caveats:
I'm not speaking on behalf of Open Philanthropy.
AI safety is a team sport — I'm standing on the shoulders of giants and did not think of all these ideas myself. I even got the idea to include this caveat from Buck’s LessWrong bio.
Some people are already working on similar projects, so most of these areas aren't totally neglected.
This shouldn’t be seen as a critique of existing projects or organizations working on similar things. I’m just saying that I want more.
I'm just one guy who hasn't thought infinitely hard about this.
These aren't necessarily the MOST impactful things to work on (there's lots of great stuff not on this list).
If you're considering these projects, you should develop your own vision for how they'd be helpful.
Applying for funding to work on these projects is by no means a guarantee you'll receive it.
If you’re interested in applying for funding to work on one of these projects (or something similar), check out our RFP.
Emphasis on “I” — these are my takes only. I'm not speaking on behalf of Open Philanthropy.
> AI tools for fact-checking
Nathan Young has an MVP extension for this.
> 3. Tracking sketchy AI agent behaviour “in the wild”
I have an MVP of this here https://docs.google.com/document/d/18e07i1-L6K4S12eLn-AwJVdAHoqBVQ4adq_n_vWGlWM/edit?tab=t.0#heading=h.67vn92etlqtm / https://github.com/NunoSempere/ai-osint-mvp
tl;dr: The individual twitter accounts I was tracking were impish but ultimately harmless.
> AI economic impacts tracker
Dan Carey might be looking for some funding to do a macroai group, but not sure if it's similar to what you are thinking of.
Interested which of these topics you think might fit a biosecurity related program more. I’m fleshing out ideas of what a good proposal might look like. Was writing today about what pandemic response might look like, and what problems biologists face.
https://drjrfelix.substack.com/p/pandemic-preparedness-has-a-biology?r=7cdtr8&utm_medium=ios